It’s not over
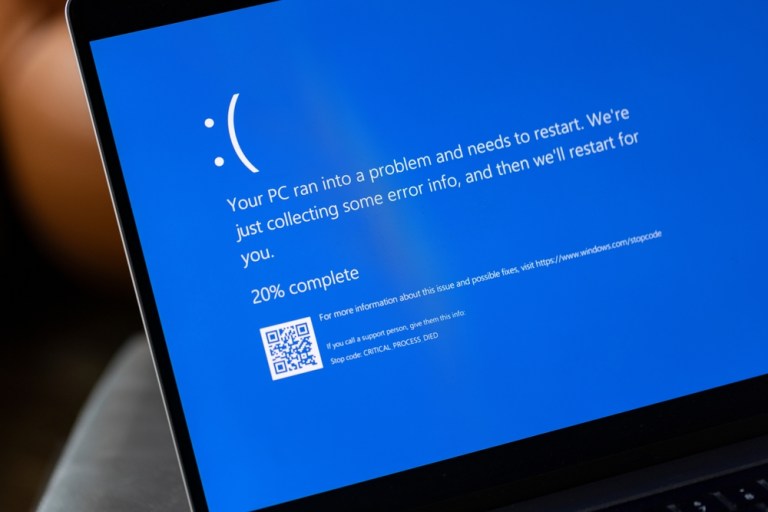
Financial institutions were temporarily hit Friday and the outage that stemmed from CrowdStrike and spread to Windows systems went deep and wide. According to DownDetector’s reading on Friday, several banks and other financial institutions were affected, but not as badly as the medical and airlines sectors. The effect on airline scheduling has been well-documented, and Wired magazine reported that several hospitals in the U.K., Australia and Israel were affected. Banks that were temporarily affected included Wells Fargo, Charles Schwab and TD Bank. While most systems are now up and running, the fix for the CrowdStrike outage is manual and will take some time.
As CrowdStrike CEO George Kurtz told NBC: “Some of the systems that aren’t recovering, we’re working with them, so it could be some time for some systems that just automatically won’t recover, but it is our mission to make sure that every customer is fully recovered and we’re not going to relent until we get every customer back to where they were and we’ll continue to protect them and keep the bad guys out of their systems.”
Be prepared for fraudster reactions
Kurtz warned CrowdStrike clients that bad actors will try and capitalize on the vulnerability exposed during the outage. According to security software provider McAfee, opportunistic scammers are seizing the moment to exploit vulnerabilities. McAfee reports a surge in fraudulent schemes, with cybercriminals employing a variety of tactics to deceive consumers. These scams span from phishing attacks disguised as flight rescheduling notices to fraudsters impersonating banks to steal login credentials. Even retailers requesting alternate payment methods have been implicated in these deceptive practices.
“As the digital landscape becomes increasingly interconnected, the importance of maintaining rigorous cybersecurity measures cannot be overstated,” a McAfee blog stated. “Consumers and organizations alike must stay vigilant, enhance their security protocols, and remain proactive in safeguarding their personal and operational data against such threats. This incident serves as a stark reminder of the cascading effects that a single point of failure can have in our globally networked environment.”
CrowdStrike and Microsoft have responded
We’d love to be your preferred source for news.
Please add us to your preferred sources list so our news, data and interviews show up in your feed. Thanks!
Crisis management was in full effect over the weekend at both Microsoft and CrowdStrike. Microsoft’s reaction, posted to its website, indicated that it was still working with its cloud service providers AWS and Google to determine the extent of the damage caused by the “blue screen of death” experienced by what it said was 8.5 million users on Friday.
Advertisement: Scroll to Continue
“This incident demonstrates the interconnected nature of our broad ecosystem — global cloud providers, software platforms, security vendors and other software vendors, and customers,” Microsoft said. “It’s also a reminder of how important it is for all of us across the tech ecosystem to prioritize operating with safe deployment and disaster recovery using the mechanisms that exist. As we’ve seen over the last two days, we learn, recover and move forward most effectively when we collaborate and work together. We appreciate the cooperation and collaboration of our entire sector, and we will continue to update with learnings and next steps.”
There is a workaround
CrowdStrike has responded with a public relations blitz and a detailed tech workaround to reinstall systems for developers. In an update provided on Sunday (July 21) the company said the Falcon Sensor system, which failed during the outage, has been restored. “We assure our customers that CrowdStrike is operating normally and this issue does not affect our Falcon platform systems. If your systems are operating normally, there is no impact to their protection if the Falcon sensor is installed,” it said.
Software updates are under the microscope
As Adam Lowe, Ph.D., chief product and innovation officer at CompoSecure/Arculus with more than a decade of experience with software updates, told PYMNTS on Friday, when a software update falters, companies typically have contingency plans to reverse the changes. However, issues with essential security software like CrowdStrike can escalate dramatically. If an update disrupts core system functions, particularly at the Windows startup level, rectifying the problem can be daunting. In such cases, it may necessitate a complete system reinstallation from a prior backup, akin to wiping a hard drive and starting anew. This process is both complex and time-consuming, especially for systems that are locked out at startup, leaving limited options for a swift resolution.
And some finger-pointing has already started. Was CrowdStrike the victim of a poor testing environment?
“I am a Certified Healthcare CIO, so I have years of background working in this field,” wrote a commentator on the Krebs on Security blog. “There is a lot of friction between the ‘new’ generation of IT leaders and my generation of IT leaders. My generation has always focused much effort on testing and regression testing of code and patches, the result being longer patch cycles. New DevOps teams want to patch more often with less testing. Both approaches have their pros and cons. This is an example of the ‘old’ way of testing being more appropriate. In my world, if we had 10 variants of Windows Operating Systems (Windows 10, release xxxxxx, Windows 11, release xxxxxx), I would require 1000 tests to be run, 100 on each variant, before we released to PROD. In today’s DevOps world, it is common to minimize testing, and just fix ‘whatever breaks’ on the backend, after-the-fact. The reality is that we need to meet in the middle between these two processes and come up with something that prevents this from happening.”